mumbai, january 2025. i'm backstage at the mumbai AI film festival at the royal opera house. on stage, amir diba (the guy behind ARQ, one of the most-watched AI filmmakers right now) is walking through his latest short.
he pulls up a number that catches my attention: 1,000+ generations for 90 final shots. a 22-page breakdown document just to keep characters looking like themselves across scenes. hours of manual culling before any creative work even begins.
i looked around the room. almost every filmmaker there was nodding. this wasn't one person's problem. this was the entire field's bottleneck.
and that's why i started building doom.
the problem
AI video models are incredible at generating a single beautiful frame. but the moment you need a character to look the same across two frames, everything breaks.
characters change faces between shots. outfits drift. skin tones shift. emotions break mid-scene. the "same character" in frame 12 looks like a different person than frame 1.
the numbers tell the story: filmmakers using tools like Runway, Kling, or Veo report a 9-14% hit rate for character-consistent outputs. that means for every 100 images generated, maybe 9 to 14 are actually usable in sequence.
"i generate 1,000+ images per project to get 90 final shots. that's a 9% yield. most of my time isn't creative work, it's culling."
paraphrased from MAFF 2025 filmmaker panel
instead of focusing on storytelling, creators spend hours manually fixing generations or regenerating until something looks right. the tools exist to make beautiful images. the missing piece: making those beautiful images look like they belong to the same story.
existing solutions (Higgsfield Soul Cast, Runway @refs, LTX Elements) hide their consistency mechanisms in black boxes. you can't see why it worked. you can't debug why it didn't. you just keep regenerating and hoping.
the approach: 3-tier DNA embeddings
doom's core idea is simple: make character identity visible, deterministic, and editable. not opaque.
every character gets a "DNA" made up of three layers:
- face embeddings: multi-angle reference sheet (front, 3/4 left, 3/4 right, side profile). the model sees the character from every angle before generating any scene.
- body type: full-body pose consistency. height, build, posture locked in from the start.
- style covenant: a frozen, verbatim prompt block that defines the visual language of the entire project. color palette, lighting rules, VFX intensity, cultural markers. this block gets copy-pasted into every single frame prompt without modification.
the three tiers work together. face embeddings handle "who is this person." body type handles "how do they move in space." style covenant handles "what world do they live in." break any one of these and consistency collapses. lock all three and you're at 95%+ across frames.
style covenant: the core innovation
the rule: freeze the style block verbatim. no paraphrasing. no summarizing. no "creative interpretation." the exact same text, copy-pasted into every prompt.
this sounds obvious but almost nobody does it. most pipelines "summarize" or "adapt" the style description per scene. the model gets slightly different wording each time. slightly different wording means slightly different output. style drift compounds frame by frame until shot 30 looks nothing like shot 1.
the style covenant is a frozen block of text. it defines:
- color palette (exact hex values or descriptive anchors)
- lighting rules (direction, warmth, contrast level)
- VFX intensity (how stylized vs. realistic)
- cultural markers (when relevant: blue skin for divine characters, specific ornament styles, iconographic rules)
- camera language (lens focal length preferences, depth of field defaults)
it's generated once during setup, approved by the user, then never touched again. every scene prompt includes it verbatim. the result: visual coherence that doesn't decay over time.
architecture
the system runs in three phases. each phase handles a different part of the screenplay-to-storyboard pipeline.
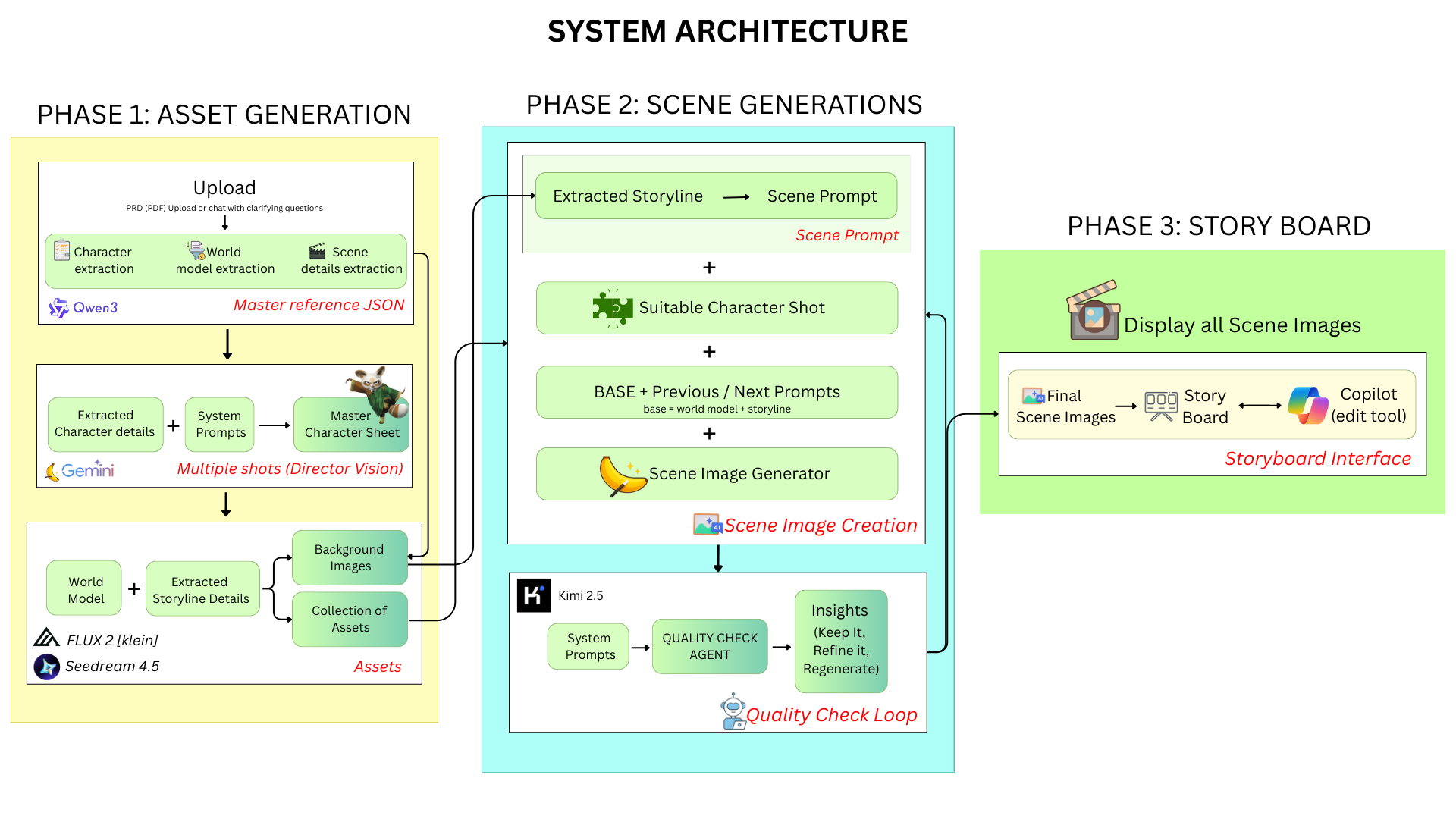
phase 1: asset generation
you upload a screenplay. could be a .txt, .pdf, or .fountain file. the system reads it and extracts everything it needs to generate visuals:
- parse: extract characters, locations, scenes from raw text
- world model: generate style tokens, mood references, cultural context for the entire story
- story summary: genre, tone, narrative arc, emotional beats
- shot plan: per-scene camera angles, lighting intent, continuity hints. this is director-level reasoning before any image exists.
- scene expansion: enrich each scene with weather, atmosphere, time of day, emotional subtext
the shot plan is what most competitors skip. they jump straight from "here's a scene description" to "generate an image." doom adds the layer between: what would a director decide about this shot before calling action? camera position. focal length. where the character stands in frame. what needs to match the previous shot for continuity.
this planning step reduces downstream rework significantly. you're not fixing compositional problems after generation, you're preventing them before.
phase 2: scene generation
this is the core loop. for each scene in the screenplay, four things happen in sequence:
reference retriever
a RAG-style system pulls the relevant assets for this specific frame: the right character angles, the world style block, background plates, and the previous scene's final image (for continuity). it's not dumping everything into the prompt. it's selecting what's relevant.
prompt composer
assembles the atomic prompt: scene description + style covenant (verbatim) + camera specifics from the shot plan + continuity hints from the previous frame. every prompt is self-contained. you could take any single prompt, run it in isolation, and it would generate something consistent with the rest of the project.
multi-reference generator
calls the image generation model with the composed prompt plus reference images (character angles, previous frame). currently using Nano Banana 2 for multi-reference support. the model sees both the text description and visual references simultaneously.
quality check judge
this is where doom diverges from "generate and hope." every output gets scored on a 6-dimension rubric before it's accepted or rejected. more on this below.
phase 3: storyboard and export
approved frames land in a timeline view. you see all your scenes laid out horizontally. from here you can:
- regenerate or refine individual frames without touching the rest
- view frame version history (every generation is kept, never overwritten)
- export a production pack: prompts formatted for Veo, Runway, Kling, or Sora, plus a shot list and style bible PDF
frame versioning is append-only. if you regenerate frame 7 three times, all three versions still exist. you can roll back anytime. this seems small but it changes how you work. you stop being afraid to experiment because nothing is ever lost.
quality check: the 6-dimension rubric
every generated frame is scored automatically before acceptance. six dimensions, weighted by importance:
| dimension | weight | how it's measured |
|---|---|---|
| character identity | 25% | face embedding cosine similarity against reference sheet |
| script adherence | 25% | vision model checks output against scene description |
| style consistency | 15% | style embedding similarity to project's style exemplars |
| visual continuity | 15% | vision model compares with previous frame (spatial, lighting) |
| technical quality | 10% | artifact detection, composition, distortion check |
| narrative impact | 10% | critical yes/no story requirements (is the sword in hand? is it raining?) |
the weights reflect what actually matters. character identity and script adherence together account for half the score. a frame can be technically perfect and stylistically coherent, but if the character doesn't look like themselves or the scene doesn't match the script, it fails.
decision ladder
once the rubric scores a frame, a decision ladder determines what happens next:
maximum 3 automatic retries per frame. if it can't hit 85 after 3 attempts, it escalates to the user with the best attempt so far and what dimension is failing. this keeps the system from burning credits on frames that need a human decision (maybe the prompt needs rewriting, not the generation).
what makes this different
shot plan (the missing layer)
most AI storyboard tools go: script in, images out. doom adds director-level reasoning between those steps. the shot plan decides camera angles, emotional beats, and continuity constraints before any image generation happens. it's the difference between "generate something for scene 5" and "generate a medium close-up, soft lighting from the left, matching the warm palette of scene 4, with the character's hand on the doorknob."
cultural attributes
doom supports cultural-specific visual rules: blue skin for divine characters in Ramayana adaptations, four-armed poses for Vishnu, divine auras, specific ornament styles. this isn't decoration. india's AI filmmaking community (MAFF, WebtoonIndia) is producing mythology-based content at scale and existing tools don't understand iconographic rules.
frame versioning
append-only. every generation is preserved with metadata (prompt used, score received, which dimensions passed/failed). you never lose a good generation because you tried to improve it. this is the same principle as git: never destroy history, always branch forward.
model-agnostic export
the style covenant and shot plan aren't locked to one image model. you can export production packs formatted for Veo, Runway, Kling, or Sora. the consistency layer lives above the generation layer. switch models without losing your visual bible.
validation
i interviewed 8 AI filmmakers from the MAFF community and adjacent circles. the signal was clear:
- 7 out of 8 said character consistency is their number one pain point
- 6 out of 8 spend $50-$200 per month on generation tools
- 5 out of 8 said they'd pay $40-$80 per month for reliable consistency
12 beta signups in the first 6 weeks, 3 from MAFF community filmmakers requesting early access. the TAM sits between $80m and $400m depending on how you scope it (indie filmmakers only vs. comics + game studios + brands).
unit economics work: at $49/month (creator tier), COGS per user is roughly $1.52. that's 97% gross margin. breakeven at ~31 users.
tech stack
- frontend
- Next.js 15 (app router), React 19, Shadcn + Tailwind
- backend
- Next.js API routes (TypeScript). full-stack monolith for MVP speed.
- database
- Supabase (postgres + auth + RLS). JSONB columns for flexible schema.
- vector search
- Qdrant (planned). in-memory cosine similarity for current MVP.
- extraction
- Claude Sonnet 4.5 for structured screenplay parsing
- composition
- Claude Haiku 4.5 for fast, cheap prompt assembly
- quality judge
- vision model (Claude Sonnet 4.5) for rubric scoring
- image gen
- Nano Banana 2 (multi-reference character consistency)
- video (optional)
- Veo 3.1 Fast (8-second clips per frame)
- storage
- Vercel Blob for reference sheets and generated frames
cost per 30-scene project: roughly $5.30. breakdown: $0.10 extraction, $2.50 character sheets, $2.25 scene generation, $0.45 quality checks.
what's next
doom is 6 weeks old. it works. characters stay consistent. the quality rubric catches drift before it compounds. but there's a lot left to build:
- human portrait library: upload real photos as character references (amir's actual method for highest consistency)
- multi-model routing: pick the best generation model per shot, not one model for everything
- audio consistency: "AI sounds and music changing every shot" is the next publicly-named pain after visual consistency
- chat/agent surface: filmmakers want to talk to their tool, not click through wizards
- environment mapping: feed the previous frame back as a reference for spatial continuity
the market timing is right. Runway raised at $5.3B. Higgsfield at $1.3B. the category is proven. what's missing is the consistency layer between "generate beautiful frames" and "generate a coherent story." that's where doom sits.
if you're an AI filmmaker, comic creator, or game studio hitting this problem, i'd love to hear how you're solving it today. reach out on twitter or email.

